A/B Testing Framework to Improve Paid & Organic Campaign Performance

Key Takeaways
- A/B testing should increase real revenue, not just clicks, traffic, or vanity numbers that look impressive.
- Pick one main goal and two safety metrics before you start any experiment.
- Test your pricing, service, and demo pages first because that’s where buying decisions actually happen.
- Write every test idea clearly: If we change this, then this will improve, because of this reason.
- Change only one important thing at a time, so you know what actually made the difference.
- Let tests run long enough to collect real data instead of stopping early when results look exciting.
- A test only wins if conversions improve without lowering lead quality or hurting profit.
- Keep a record of every test so lessons build over time instead of being forgotten.
Most marketing teams don’t actually have a traffic problem; they have a clarity problem. Budgets go up, impressions grow, rankings improve; on paper, everything looks like progress. But conversions stay flat, and that’s not random; it’s feedback. Without a structured A/B testing framework, optimization turns reactive: performance dips, you change the headline; CTR drops, you swap the creative; a competitor redesigns, you panic-redesign too. The issue isn’t effort; it’s control. When multiple variables move at once, you can’t prove what worked, and you can’t repeat it.
A real testing system brings discipline. You change one variable, document one hypothesis, and decide in advance which metric matters most. That structure removes ego from the process. Instead of debating what “feels” stronger, you let user behavior tell you what drives qualified leads, revenue per visitor, and sustainable growth. Over time, the impact compounds: winners become the new baseline, and even “losing” tests teach you what your audience actually cares about.
When paid and organic teams align around shared performance goals, content becomes the bridge between SEO and PPC. It becomes intentional, measurable, and predictable; the difference between running random experiments and building a growth engine that learns faster than competitors.
In this blog, we’ll walk through a practical A/B testing framework designed to improve both paid and organic performance, without draining budget on activity that looks productive but teaches you nothing. You’ll see how to prioritize what actually deserves testing, how to form hypotheses grounded in real user behavior (not opinions), how to measure outcomes in a way that avoids false winners, and how to turn individual test results into a structured system that builds insight, and performance, over time.
Why A/B Testing Drives Marketing Success
Modern marketing runs on assumptions disguised as strategy, like trying to tune a radio while three people keep spinning the dial. Creative argues headlines, paid tweaks bids, SEO rewrites pages, and the business stares at a graph that moved, but nobody knows why. A disciplined A/B testing framework is the “one hand on one dial” rule: change one variable, hold the rest steady, and let real user behavior decide what deserves more budget, more traffic, and more trust.
The 3-Point Reality Check:
- One lever: Change one thing. If you touched the headline + layout + offer, that’s not a test; that’s a remix.
- One scoreboard: Judge on the metric that pays you (qualified leads/revenue per visit), not the one that makes a chart look happy.
- One shipping trigger: “If it clears X% lift and quality holds, we roll it out. If not, we log it and move on.”
The 7-Step A/B Testing Framework
- Pick one primary metric– qualified leads, revenue per visitor, sales-accepted opps.
- Set 2 guardrails– lead quality, CPA/CPL, refund rate, bounce rate; whatever protects the business.
- Name the bottleneck– promise gap, objection, friction, trust, pricing clarity.
- Write one hypothesis: If we ___, then ___, because ___.
- Change one lever only– headline, offer framing or, proof placement, don’t remix.
- Pre-set decision rules– minimum runtime + minimum conversions + what “ship” means.
- Document + standardize– winner becomes baseline; loser becomes a lesson; inconclusive becomes a better next test.
Here’s why “small changes” can hit big: the right micro-shift removes doubt at the exact moment someone decides. A clearer value props above the fold, a more specific CTA, or a trust signal beside the form isn’t cosmetic; it’s intent alignment. That’s how you improve campaign performance with A/B testing without buying more traffic: you make existing clicks behave better. And the upside compounds; WordStream reports an average 7.52% conversion rate and an average CPL of $70+ across industries. A 10–15% lift isn’t “nice,” it’s leverage.
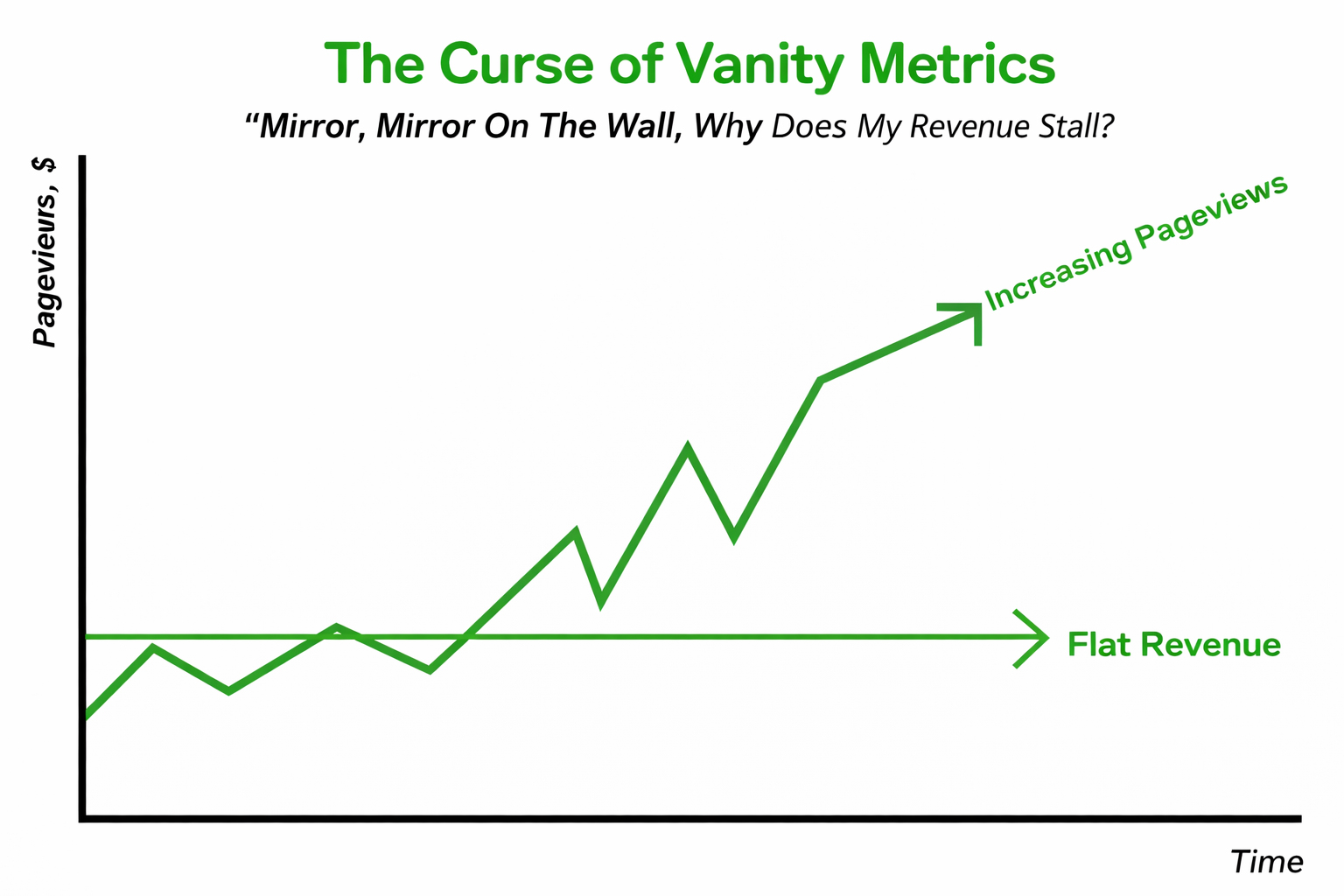
Are You Testing Revenue or Vanity Metrics?
CTR is flattering. Revenue is unforgiving. Many teams celebrate higher click-through rates or session growth, only to discover pipeline numbers remain unchanged. That disconnect occurs when you test surface metrics rather than business outcomes. A strong A/B testing framework anchors experiments to qualified conversions, not engagement theatre.
Organic visibility is extremely competitive. Backlinko’s analysis of 4 million Google results found the #1 result averages a 27.6% CTR, and the top 3 results get 54.4% of all clicks. In short, when you do win high-intent clicks, wasting them on a weak conversion experience is expensive. That means traffic concentration is real, and wasting high-intent clicks on weak conversion experiences is expensive. This is where conversion rate optimization testing becomes non-negotiable.
The solution is alignment. Choose one primary metric tied directly to revenue (qualified leads, revenue per visitor, or sales-accepted opportunities). Then define guardrails, such as lead quality or cost per acquisition, to protect downstream performance. Before launching any test, predefine your minimum detectable lift and statistical threshold. If the change doesn’t plausibly impact revenue, it doesn’t deserve traffic. Marketing maturity begins when teams optimize for business impact, not dashboard aesthetics.
What to Test First (So You Don’t Waste Traffic)
Prioritize tests using a simple score:
Priority Score = (Impact × Confidence) ÷ Effort (1–5 each)
Start where intent is highest:
- Pricing page
- Service page CTA section
- Demo/consultation landing page
- Lead form step/booking flow
If a test can’t realistically move revenue (or qualified leads), it’s not a priority, no matter how “easy” it is.
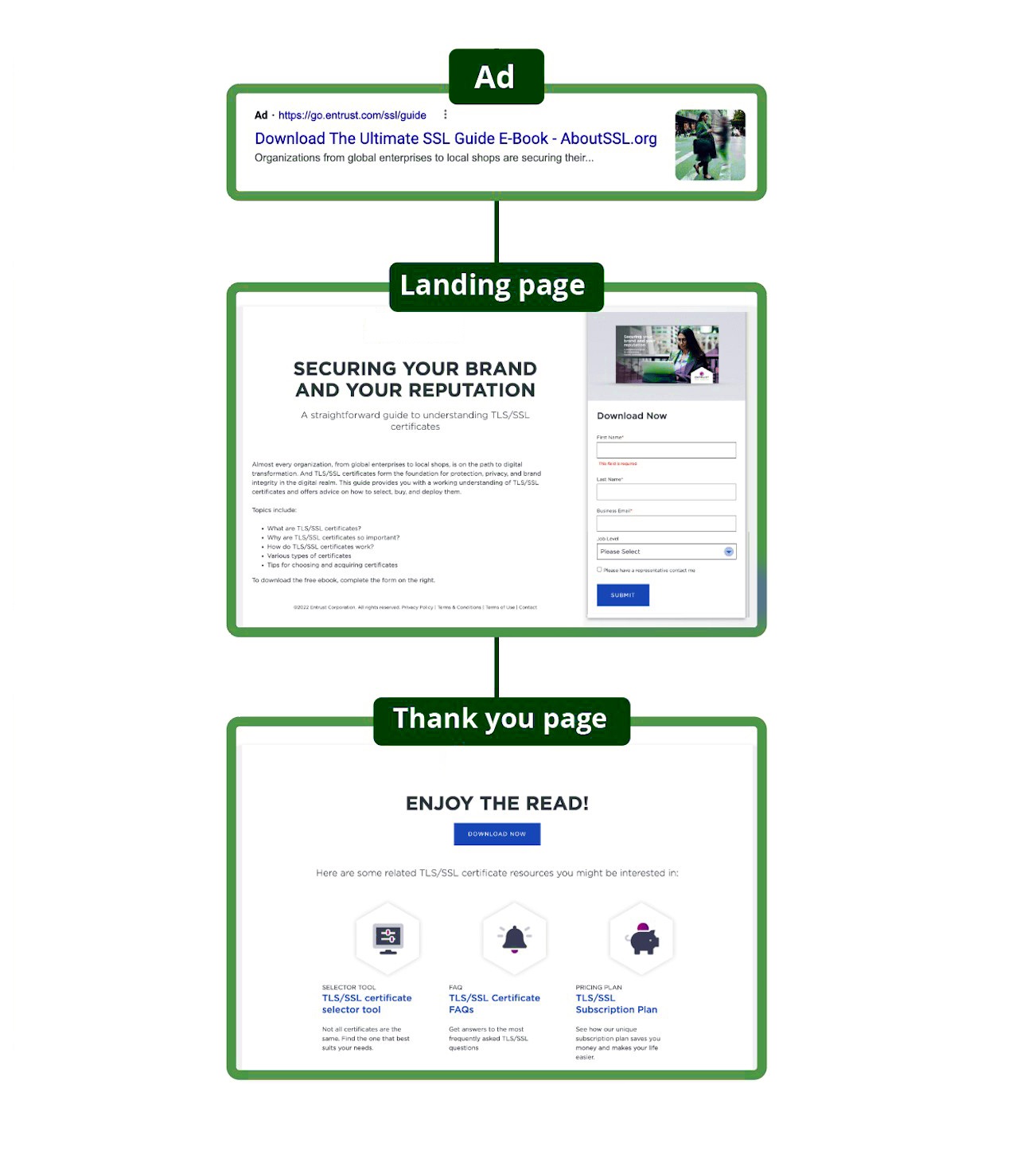
Does Your Landing Page Match the Promise?
Every click carries an expectation. If your landing page doesn’t confirm that expectation immediately, hesitation kicks in, and hesitation kills conversions quietly. The most common leak isn’t “bad traffic,” it’s a promise gap: your ad says one thing, your page says something else, and the user feels like they walked into the wrong meeting.
Speed makes that gap brutal, especially when core web vitals and user experience performance are neglected. Google reports that 53% of mobile users abandon a page that takes longer than 3 seconds to load. When speed and clarity fail together, abandonment accelerates fast. That’s why paid ad split testing can’t stop at creative alone; you have to validate the landing experience too, otherwise you’re optimizing the click and ignoring the conversion.
Use this simple tutorial framework:
The 3-Second Promise Match:
Step 1: Echo the offer in the hero using the same wording from the ad (if the ad says “Free 15-Minute Audit,” the hero should say it too, clearly).
Step 2: Add proof above the fold (one concrete credibility cue).
Step 3: Make the next step frictionless (short form, clear CTA, obvious “what happens next”).
Then run structured landing page testing using principles from high-performing lead generation websites, and apply a focused headline testing strategy that prioritizes specificity over cleverness. Judge success by qualified conversions, not just submissions, because people convert when they feel certain, not persuaded.
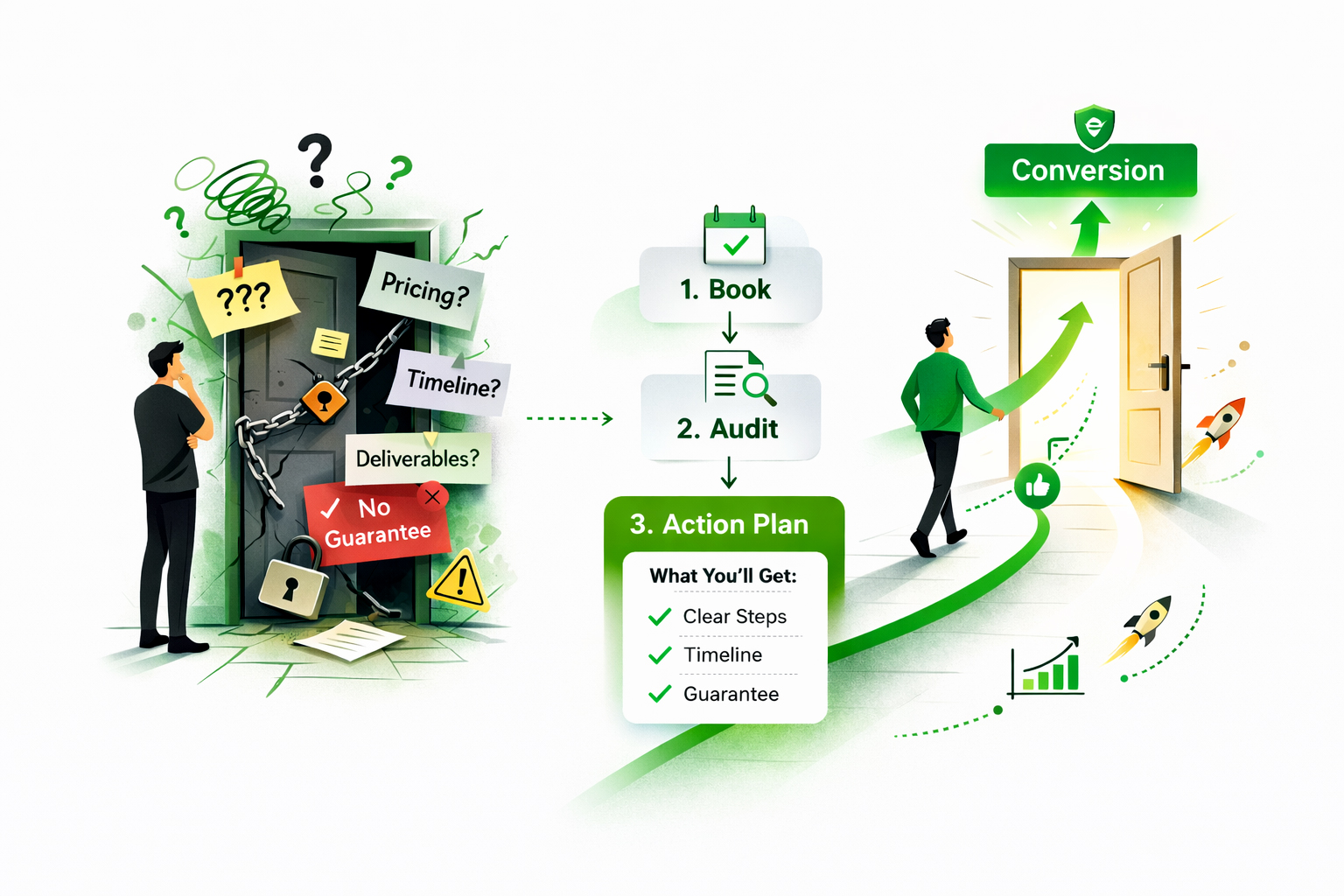
Are You Solving Doubt or Just Designing?
Redesigns are loud. Doubt removal is profitable. Most teams repaint the house, even though the real issue is that the front door doesn’t open smoothly. Quick question: when someone lands on your page, can they answer
“What do I get?”
“How long does it take?”
“And what happens next?”
In under 10 seconds? If not, you don’t have a design problem; you have a confidence problem. Pricing ambiguity, unclear timelines, and missing guarantees are classic reasons why poor UX costs businesses real leads. And hesitation is the silent killer of conversions because people don’t complain; they just disappear.
Story break: A small SaaS brand came in convinced they needed a “modern refresh.” The real issue? Their demo page never explained what the demo actually included. We didn’t redesign first; we ran conversion-rate optimization tests. One change: a simple 3-step process (“Book → Audit → Action Plan”) and a short “What you’ll receive” box near the CTA. Conversions jumped, not because the page was prettier, but because it felt safer. That’s the power of CRO experimentation: it tests reassurance, not aesthetics.
Now zoom out: speed is also part of doubt. If the page lags, users subconsciously question reliability. Studies and industry reporting show that even small page-load delays can significantly reduce conversions, underscoring the need for speed and clarity to work together. Treat each change like a marketing experiment: pick one objection, change one variable, define one primary metric and guardrails, and run it long enough to trust the result.
Ask yourself: What would make a reasonable buyer feel certain right here? Then test that.
Paid vs. Organic Traffic: Behavior Differences
Paid and organic traffic may land on the same page, but intent often differs. Paid visitors typically arrive closer to the decision stage. Organic visitors frequently seek validation, comparison, or a deeper understanding. Treating both audiences identically can suppress performance.
A strong SEO A/B testing strategy examines post-click behavior by channel, not just aggregate results. Segment your experiment data by conversion rate, source, device, and engagement depth. A variant may improve paid conversions while reducing organic session depth, and both can be true.
Layer in PPC optimization testing guardrails, such as ROAS and lead quality for paid, while tracking engagement metrics and assisted conversions for organic. The goal is alignment, not uniformity. Action plan: build segmented dashboards, define channel-specific success indicators, and personalize content modules when necessary. When messaging matches the user intent stage, conversion improves without increasing acquisition costs.
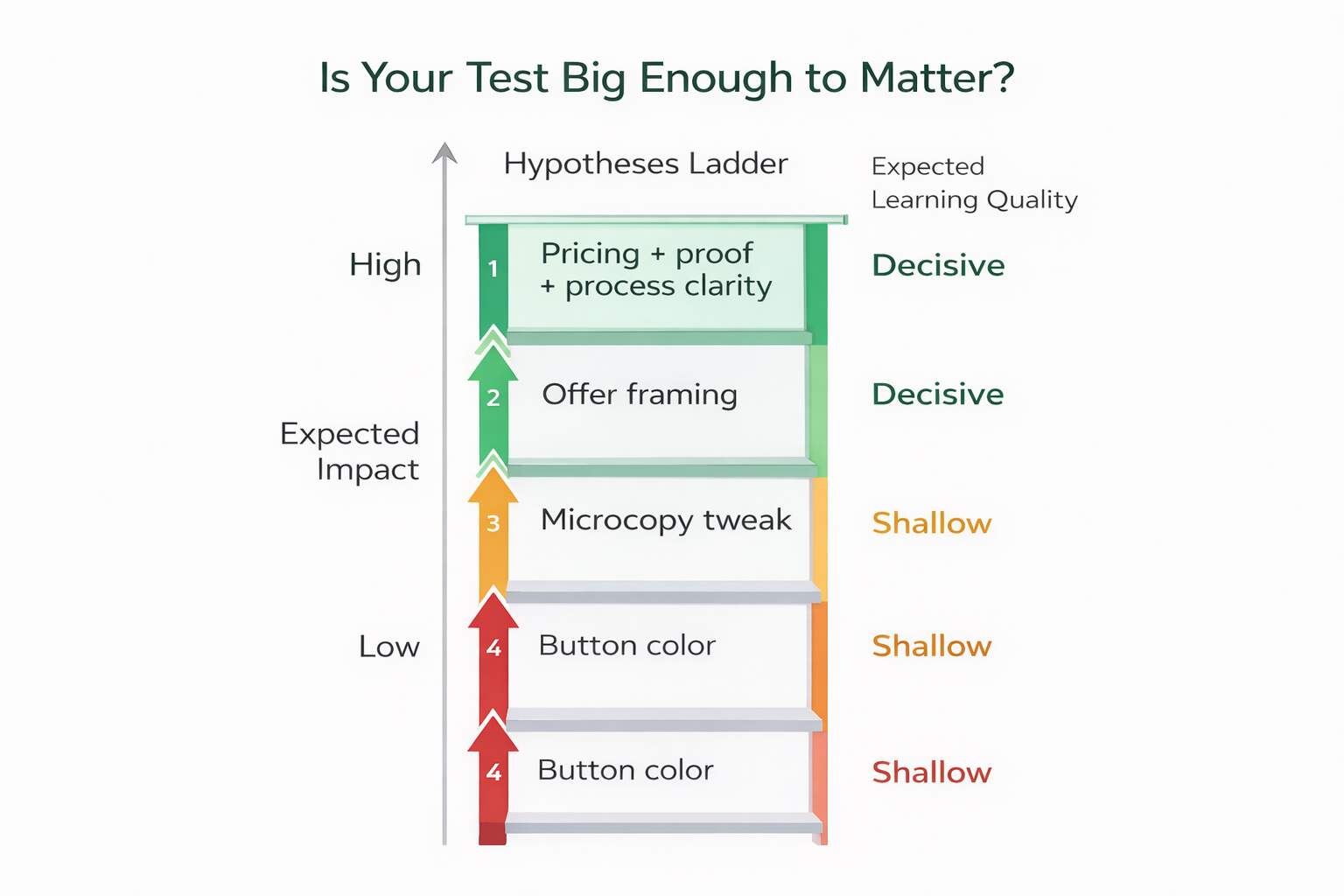
Is Your Test Big Enough to Matter?
Small tests often produce small insights. Changing button colors or micro-copy rarely shifts decision psychology. Worse, minor changes require significant traffic to detect meaningful differences, which increases the risk of “meh” results that waste time and teach nothing. If the best-case upside is tiny, the learning will usually be tiny too, and that’s how teams stay busy without getting better.
Optimize explains that detecting small effect sizes requires larger sample sizes and longer runtimes, which many businesses underestimate. Instead of incremental tweaks, prioritize meaningful shifts, offer framing, pricing visibility, objection handling, or content hierarchy adjustments. These are the high-leverage changes users actually notice, and they’re more likely to create decisive learning.
Here are 4 “big enough to matter” ideas to use in split testing campaigns:
- Offer clarity vs. feature list: “Get X outcome in Y time” vs. “Here are 10 features.”
- Pricing transparency vs. hidden pricing: pricing range above the fold vs. pricing later (or not at all).
- Proof near CTA vs. proof mid-page: testimonials/logos right beside the action vs. buried lower.
- Process-first vs. result-first structure: “How it works” first vs. “What you get” first.
Think in terms of split testing campaigns that change core value communication, not decorative elements. Define your minimum meaningful lift threshold (e.g., 10–15%), score ideas by impact and feasibility, and prioritize high-intent pages first. Effective testing isn’t about running more experiments; it’s about running decisive ones. Bigger hypotheses generate clearer learning faster.
Two High-Leverage Test Examples
![]() Example 1: Offer clarity vs feature list
Example 1: Offer clarity vs feature list
- Hypothesis: If we lead with outcome + timeframe, qualified leads will rise because buyers decide faster.
- A: “10 features…”
- B: “Get X outcome in Y time” + 3 bullets of what’s included
- Primary metric: qualified lead rate
- Guardrails: lead quality, CPL/CPA
- Decision: ship only if quality holds.
![]() Example 2: Proof beside CTA vs. proof buried
Example 2: Proof beside CTA vs. proof buried
- Hypothesis: If we place proof beside the form, the conversion rate will increase because perceived risk drops at the decision point.
- A: testimonials mid-page
- B: 2 testimonials + logos directly beside form
- Primary metric: revenue per visitor / qualified conversion rate
- Guardrails: spam lead rate, sales-accepted rate
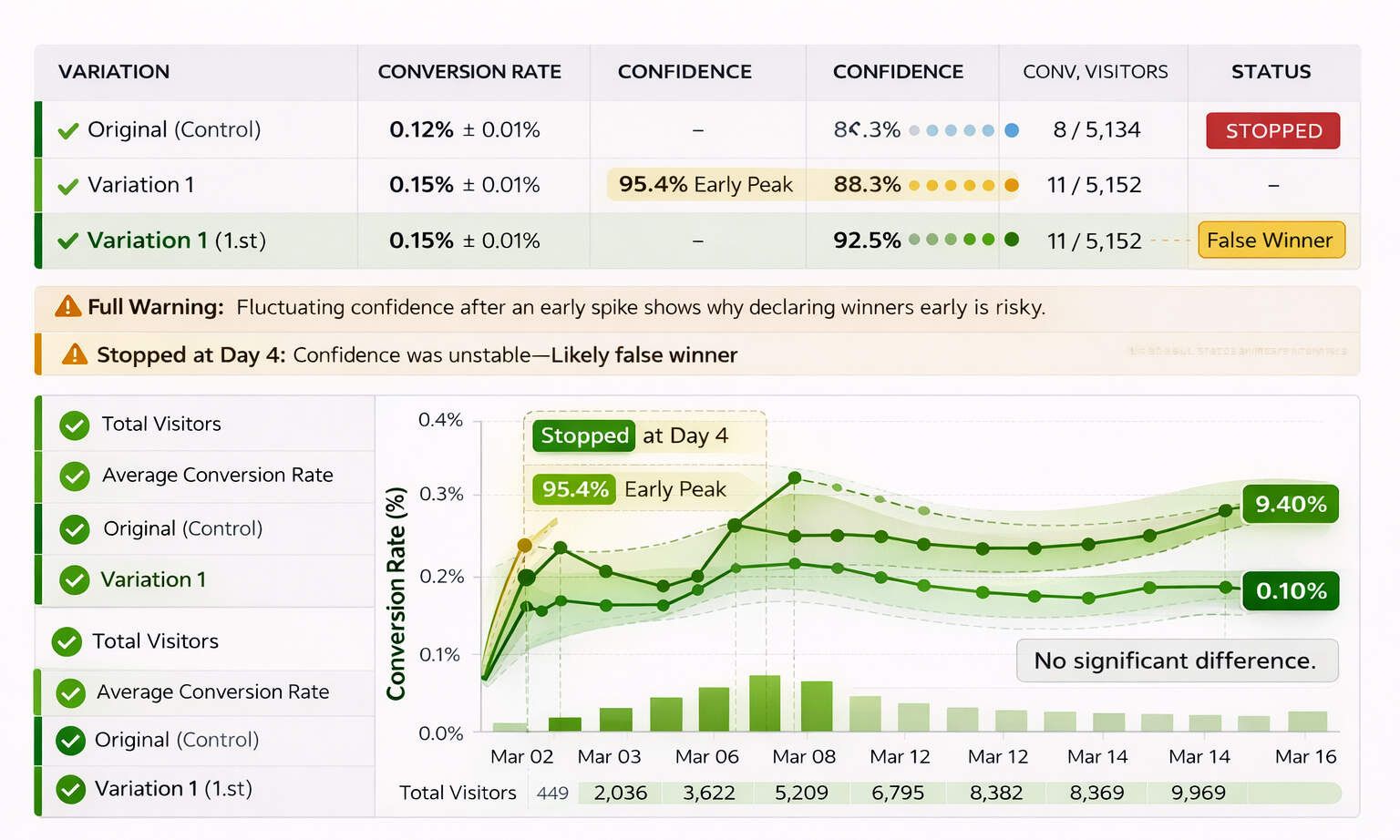
Are You Calling Winners Too Early?
Early performance spikes are seductive. But short-term gains often reflect traffic fluctuations, learning phases on the platform, or randomness, not real improvement. Declaring winners prematurely is one of the most expensive mistakes in testing.
CXL recommends running tests long enough to capture full business cycles, often 2–4 weeks, depending on volume. Adobe also notes that even at 95% confidence, false positives remain statistically possible, especially when teams check results repeatedly and stop opportunistically.
Implement structured statistical significance testing rules before launch: minimum runtime, minimum conversion thresholds, and predefined decision criteria. Avoid mid-test edits, maintain stable budgets, and validate lead quality alongside conversion rate. Scaling a false winner compounds losses faster than scaling a true winner compounds gains. Discipline protects growth.
Do You Have a System or Random Tests?
Testing without documentation is just structured guessing. Many teams run experiments but fail to record hypotheses, conditions, results, or rollout decisions. That breaks compounding learning.
A mature program operates under experiment-driven marketing principles: every test is logged, categorized, and analyzed for patterns. Track hypothesis, audience segment, variable tested, primary metric, guardrails, runtime, and outcome. Over time, you’ll identify repeatable principles, such as clarity outperforming cleverness or proof near CTAs consistently improving performance.
Treat this as your ongoing performance testing framework. Winners become standards. Losers become lessons. Inconclusive results refine backlog priorities. Schedule consistent testing cadence; one meaningful test per month beats constant low-impact experimentation. When structured correctly, testing becomes a growth engine rather than a reactive tactic.
Final Note
At this point, the takeaway should be uncomfortable (in a good way): most “optimization” work doesn’t fail because teams lack ideas; it fails because teams lack a repeatable decision system. A real A/B testing framework gives you that system. It forces you to pick one lever, write one prediction, measure one business outcome, and stop crowning winners early. When you do this consistently, paid stops bleeding budget into vague traffic, and organic stops driving sessions that never convert. You don’t just get “better marketing.” You get marketing that learns faster than competitors.
The real edge is compounding. One test improves one page. The next test locks in a proven pattern. Over a quarter, you stop relying on hero campaigns and start relying on a process that keeps improving even when platforms change the rules. And because testing aligns PPC and SEO around the same outcome (qualified revenue), it stops internal debates and turns performance into something you can forecast.
Finally, this is what separates “we tested a few things” from “we run a growth engine.” You’re not chasing hacks, you’re building a culture where every change earns its place, and every result (win or loss) sharpens the next decision. That’s how performance becomes predictable.
Stop Guessing. Start Compounding
Want a revenue-first testing plan built for both paid and organic, including hypotheses, tracking, execution, and rollout? eSign Web Services can help. Book a Campaign Optimization Audit and turn your next 90 days into measurable, compounding growth.
Frequently Asked Questions (FAQs)
Question: What is an A/B testing framework in marketing?
Answer: An A/B testing framework is a structured system for running controlled experiments that compare two versions of a page, ad, or funnel element to determine which performs better. Instead of guessing, teams form hypotheses, prioritize ideas, define success metrics, run controlled tests, and analyze results. A strong framework aligns experiments with revenue goals rather than vanity metrics. It also includes guardrails, documentation, and rollout rules to ensure improvements are sustainable and scalable.
Question: How does A/B testing improve both paid and organic performance?
Answer: A/B testing improves both channels because paid ads and organic traffic often land on the same pages. When you optimize clarity, reduce friction, and increase trust, conversion rates improve regardless of traffic source. Paid benefits from stronger return on ad spend, while organic benefits from improved engagement and satisfaction. Testing shared landing pages creates compounding gains. Instead of optimizing channels separately, you improve the core experience that drives performance across all acquisition efforts.
Question: What should be the primary metric in A/B testing?
Answer: Your primary metric should reflect real business impact, such as qualified leads, revenue per visitor, pipeline contribution, or return on ad spend. Avoid using surface metrics like clicks or time on page as primary decision factors. Supporting metrics, called guardrails, should protect quality and long-term value. For example, if conversion rate increases but lead quality drops, that’s not a true win. The right primary metric ensures tests drive profitability, not just activity.
Question: How long should an A/B test run?
Answer: An A/B test should run long enough to collect sufficient conversions and cover normal traffic fluctuations. Most tests require at least one to two full business cycles, including weekday variations. Stopping early increases false positives and unreliable conclusions. Define minimum runtime and conversion thresholds before launching. Paid campaigns especially need stabilization time due to algorithm learning phases. Testing patience prevents premature decisions that could lock in underperforming versions.
Question: Can small changes like button color improve performance?
Answer: Small changes occasionally produce incremental lifts, but meaningful growth usually comes from structural improvements. High-impact tests address messaging clarity, pricing transparency, objection handling, trust signals, and offer framing. Cosmetic changes rarely shift user psychology in measurable ways. If a test cannot reasonably influence user confidence or decision-making, its potential impact is limited. Prioritize experiments that directly reduce doubt or friction instead of visual adjustments alone.
Question: Should paid and organic traffic be tested separately?
Answer: Not always separately, but always analyzed separately. Both channels may share the same landing page, yet visitor intent differs. Paid visitors are often closer to a decision, while organic visitors may still be researching. Segmenting test results by channel reveals whether variants perform differently across audiences. If performance diverges, consider personalized messaging by traffic source. Testing without segmentation risks implementing changes that help one channel while harming another.
Question: What is statistical significance in A/B testing?
Answer: Statistical significance measures whether observed differences between variants are likely due to real impact rather than random chance. Without statistical confidence, test results may mislead decision-making. Confidence thresholds, commonly 90–95%, help ensure reliability. However, significance alone is not enough, practical significance matters too. A statistically significant 1% lift may not justify rollout if the business impact is minimal. Strong testing balances statistical rigor with strategic value.
Question: How do you prioritize which tests to run first?
Answer: Prioritize experiments using an Impact–Confidence–Ease framework. Evaluate potential business lift, evidence supporting the hypothesis, and implementation effort. Focus first on high-impact, high-confidence tests affecting critical funnel stages like landing pages, pricing pages, or checkout flows. Avoid prioritizing ideas simply because they are easy to execute. Strategic prioritization ensures testing resources target meaningful growth opportunities instead of low-value experiments.
Question: What are guardrail metrics in A/B testing?
Answer: Guardrail metrics protect against unintended negative consequences. While your primary metric determines the winner, guardrails ensure quality isn’t compromised. For example, if conversion rate increases but refund rates rise or average order value drops, the change may harm profitability. Guardrails commonly include bounce rate, lead qualification rate, customer lifetime value, and engagement depth. Monitoring these alongside primary metrics prevents short-term wins from becoming long-term losses.
Question: How do you scale winning A/B test results?
Answer: Scaling requires controlled rollout, documentation, and pattern application. First, gradually deploy the winning variant to ensure stability. Then document the hypothesis, audience, result, and insight for future reference. Over time, identify recurring patterns, such as clearer pricing or stronger proof consistently winning. Apply these principles across other pages and campaigns. Scaling is not copying one win; it’s turning repeated learnings into standardized optimization playbooks.
Author Details

Ashwani Kumar Sharma
Ashwani has been actively involved in SEO services since 2005. His expertise and distinctive work approaches have made him one of the most experienced and trusted SEO experts in the industry. He is a certified SEO and Google Ads professional. He also has strong business development skills in advanced SEO, PPC, and digital marketing strategies.